| akzy | Дата: Воскресенье, 23.06.2013, 19:55 | Сообщение # 1 |
|
Лейтенант
Группа: Пользователи
Сообщений: 55
Награды: 0
Репутация: 3
Статус: Offline
| перевод оригинальной статьи
(в кратце статья показывает, чего следует избегать и к чему следует стремится. Поскольку часть терминов непереводима, приведена ближайшая аналогия)
28.1 Обзор
За последние несколько лет, конвейеры рендеринга с аппаратным ускорением
резко увеличилось по сложности, принеся с собой все более сложные и запутанные характеристики. Повышение производительности использовавшегося для обозначения простого сокращения циклов процессора внутренних циклов в визуализации, теперь стало циклом определения узких мест и систематически бороться с ними. Этот цикл идентификации и оптимизации имеет фундаментальное значение для настройки гетерогенных многопроцессорных систем; движущая идея в том, что конвейер (pipeline), по определению, не быстрее, чем его самый медленный участок. Таким образом, в то время как преждевременная и сфокусированная оптимизация в однопроцессорной системе может привести к минимальным приростам производительности в многопроцессорных системах такая оптимизация очень часто приводит к нулевым выгодам.
То есть, если мы прилагаем все усилия по оптимизации графики и видим нулевое повышение производительности, это не очень хорошо. Цель этой главы- держать вас от этого подальше.
28.1.1 конвейер
(Pipeline)
Конвейер , на самом высоком уровне, можно разбить на две части: центрального и графического процессора. Хотя CPU оптимизация является важной частью оптимизации приложения, он не будет в центре внимания этой главы, потому что большая часть этой оптимизации не имеет ничего общего с графическим конвейером.
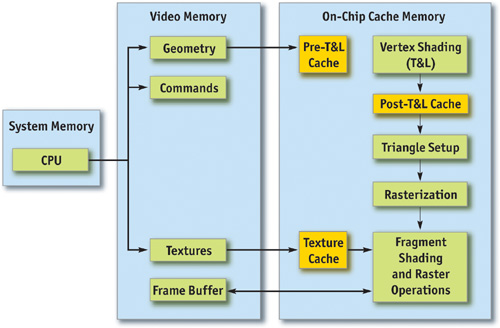
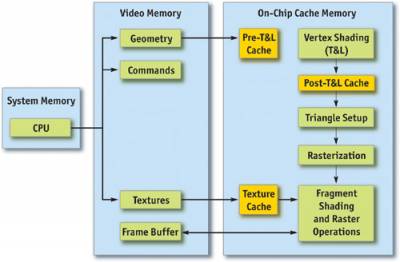
Рисунок 28-1 показывает, что в ГПУ (буквально, процессоре видеокарты, GPU), существует множество функциональных блоков, работающих параллельно, которые по большей части действуют как отдельные процессоры специального назначения, а также количество мест, где может возникнуть узкое место. К ним относятся вершины и индексы выборки, вершинные (трансформации и освещения, или T & L), фрагмент теней и растровых операций (ROP).
Оптимизация без надлежащей идентификации узких мест является причиной многих впустую потраченных усилий в области развития, и поэтому мы должны формализовать процесс на следующие фундаментальные идентификации и оптимизации цикла:
Найти узкое место. Для каждого этапа в конвейере , либо изменяются его рабочая нагрузка или ее вычислительные возможности (то есть, тактовая частота). Если производительность меняется, вы нашли узкое место.
Оптимизация. Учитывая бутылочной этап, сократите рабочую нагрузку, пока не производительность не улучшится или, пока не достигнете желаемого уровня производительности.
Повтор. Выполните шаги 1 и 2, пока нужный уровень производительности не будет достигнут.
28.2 Поиск Узких мест
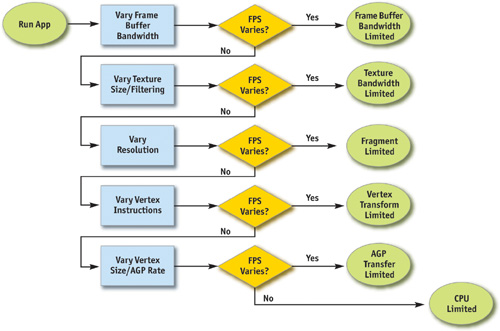
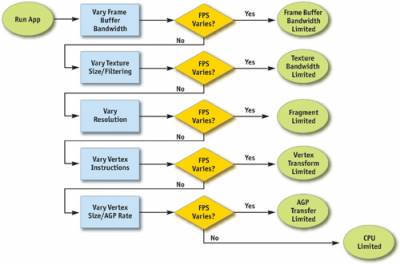
Поиск узких мест является залогом успеха в оптимизации, потому что она позволяет принимать разумные решения о сосредоточении усилий вашей фактической оптимизации. Рисунок 28-2 показывает блок-схему последовательности шагов, необходимые для точного нахождения узкого места в приложении. Обратите внимание, что мы начинаем с заднего конца конвейера , с буфера кадра операций (так называемые растровые операции) и заканчиваем в процессоре. Отметим также, что любой примитив (обычно в виде треугольника), по определению, имеет одно узкое место,а на протяжении кадра узкое место, скорее всего, изменяется. Таким образом, изменение нагрузки на более чем одной стадии в конвейере часто влияет на производительность. Например, низкополигональный скайбокс часто связан с затенением фрагмента или доступом к буферу фреймов, скелетный меш, который отображает только несколько пикселей на экране часто связан с процессором или обработкой вершин. По этой причине, это часто помогает варьировать нагрузки на объект-на-объект или материала-на-материал.
Для каждого этапа конвейера, отметим также графический процессор, к которому он привязан (то есть, основной или памяти). Эта информация полезна в сочетании с такими инструментами, как PowerStrip (Тайвань EnTech 2003), которая позволяет сократить соответствующие тактовые частоты и наблюдать изменения производительности в приложениях.
продолжение следует....
Сообщение отредактировал akzy - Воскресенье, 23.06.2013, 20:43 |
| |
| |